


















Order Tramadol Online Any complex system can be abstracted in a simple way. Complexity arises by the accumulation of several simple layers. The goal of this post, is to explain how neural networks work with the most simple abstraction.
Order Valium OnlineBuy Ambien Online Without Prescription A supervised neural network, at the highest and simplest abstract representation, can be presented as a black box with 2 methods learn and predict as following:
https://clinicakemana.com/aviso-legal/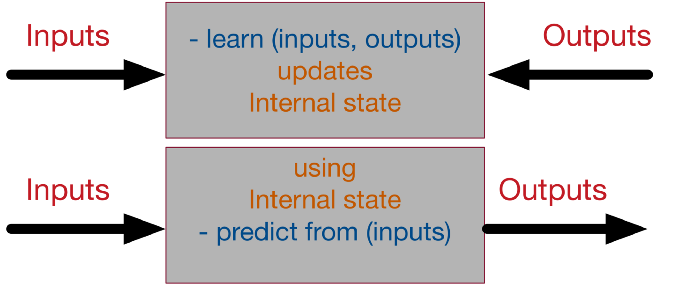
Buy Xanax Online Overnight Before understanding backward propagation, we need to understand forward propagation first. What we do in forward propagation? Let’s understand this with example. For example, we are making neural network for logistic regression. Now we know that, for logistic regression we have equation y=wTx+b where ‘T’ means transpose. Now what we do in gradient descent method is we try to minimize parameter “W” and “B” in equation so that model should predict correct values. In most cases we try to minimize values of W and B by following formula
https://champions-pd.com/finances/ where w is parameter which we are minimizing, dw is dJ/dw, a is Some learning rate. This kind of equation can be called iterative method for finding minimal value of w.
https://aizaranistore.com/index.php/wishlist/ Now, when we talk about forward propagation, so in neural nets when we go from left to right means we are going be computing some values like activation function.
https://fireaid.com/security/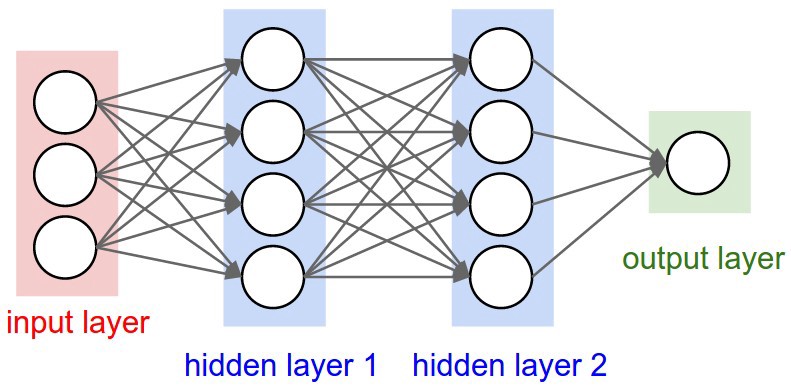
Buy Valium Online Without Prescription If we are going from hidden layer 1 to hidden layer 2 with the help of some activation function and after the end of the hidden layer 2 we are having some output value as well as we are now having some values of W and B. Now we will check our desired output and compare it with actual output and based on that back propagation will be initiated. Suppose, we are doing binary classification and we are not getting output as expected so now back propagation method will be followed in order to get proper values of W and B with the help of differentiation.
https://stephenjressler.com/publications/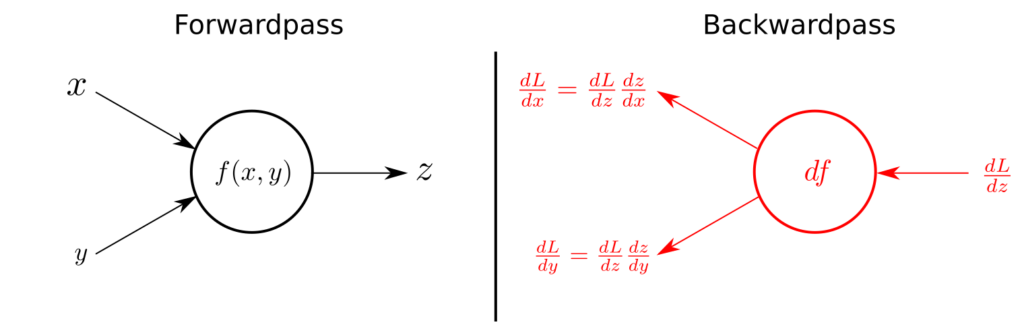
Buy Hydrocodone Online Overnight In this way, our values of W and B will be improved and then after training on data it will give us output as we want from neural nets.
Xanax Buy Without PrescriptionBuy Hydrocodone Online Overnight















